Bij regressie kijken we naar de relatie tussen één of meerdere onafhankelijke variabelen (x) en de afhankelijke variabele (y). De meest simpele vorm van regressie is een rechte lijn, waarbij er sprake is van 1 x, en de vorm kan worden geschreven als y = a + bx.
y : de afhankelijke variabele, of de uitkomst
b : helling (of stijging)
a : de intercept (daar waar de lijn de y-as kruist waar x = 0)
x : de onafhankelijke variable (de input)
Je kunt hiervoor gebruik maken van een tabel:
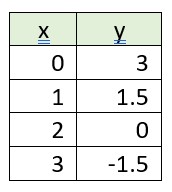
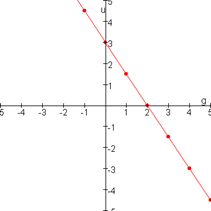
Voor elke toename van x + 1, neemt y met 1.5 af.
Daar waar x = 0 is y: 3, de intercept is hier 3; de helling is dan -1.5
Kijk nu naar de volgende tabel:
| # | ENGINESIZE | CYLINDERS | FUELCONSUMPTION_COMB | CO2EMISSIONS |
| 1 | 2 | 4 | 8.5 | 196 |
| 2 | 2.4 | 4 | 9.6 | 221 |
| 3 | 1.5 | 4 | 5.9 | 136 |
| 4 | 3.5 | 6 | 11.1 | 255 |
| 5 | 3.5 | 6 | 10.6 | 244 |
| 6 | 3.5 | 6 | 10 | 230 |
| 7 | 3.5 | 6 | 10.1 | 232 |
| 8 | 3.7 | 6 | 11.1 | 255 |
| 9 | 3.7 | 6 | 11.6 | ? |
De vraag is of we voor # 9 de uitstoot kunnen berekenen [y] aan de hand van de gegevens in de kolommen: EngineSize, Cylinders en FuelConsumption_Comb [x].
We maken hiervoor gebruik van multiple linear regression, met als gegeven input [x], en we zoeken de voorspelling van y, ŷ (uitgesproken als y-hat).
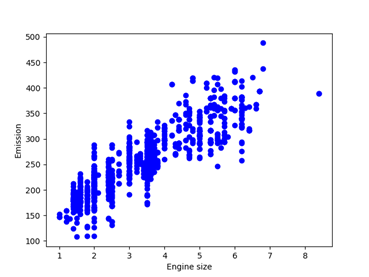
Laten we eerst kijken naar simple linear regression, waarbij gebruik gemaakt wordt van 1 input variabele, bijvoorbeeld de grootte van de motor. Als we dit plotten in een grafiek, zien we al snel dat de grootte van de motor samenhangt met de uitstoot.
Als we nu meer variabelen toevoegen aan de berekening, dan wordt al snel zichtbaar dat ook hier verbanden bestaan:
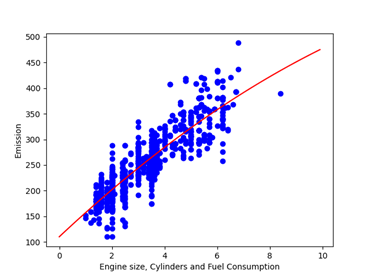
Hierdoor ziet de berekening er als volgt uit:
CO2EM = Ɵ0 + Ɵ1x1 + Ɵ2x2 + … + Ɵnxn
Of als vector:
Ŷ = ƟTx
Waarbij ƟT = [Ɵ0 , Ɵ1 , Ɵ2 , …] de parameters zijn en x de featureset (in dit geval de auto met zijn eigenschappen).